Case
A client of mine had some performance issues with couple of SSIS packages and because they lack basic SSIS knowledge, they just upgraded there server with more memory. Finally, after 32GB of memory, they stopped upgrading and start reviewing there packages.
Solution
There are a lot of blogs about SSIS Best Practices (for instance:
SSIS junkie). Here is the top 10 of the easy to implement but very effective ones I showed them to 'upgrade' their packages instead of the memory.
1) Unnecessary columns
Select only the columns that you need in the pipeline to reduce buffer size and reduce OnWarning events at execution time. SSIS even helps you by showing the unnecessary ones in the Progress/Execution Results Tab:
[DTS.Pipeline] Warning: The output column "Address1" (16161) on output "Output0" (16155) and component "CRM clients" (16139) is not subsequently used in the Data Flow task. Removing this unused output column can increase Data Flow task performance.
 |
| Unnecessary columns from a flat file |
2) Use queries instead of tables
Following on the unnecessary columns, always use a SQL statement in an OLE DB Source component or (Fuzzy) Lookup component rather than just selecting a table. Selecting a table is akin to "SELECT *..." which is universally recognised as bad practice.
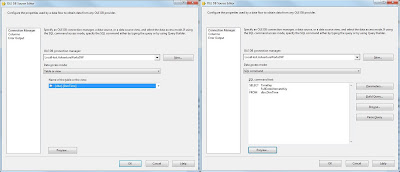 |
| OLE DB Source, use SQL Command instead of Table |
 |
| Lookup, use SQL Command instead of Table |
3) Use caching in your LOOKUP
Make sure that the result of your lookup is unique, otherwise SSIS cannot cache the query and executes it for each record passing the lookup component. SSIS will warn you for this in the Progress/Execution Results Tab:
[Lookup Time Dimension [605]] Warning: The component "Lookup Time Dimension" (605) encountered duplicate reference key values when caching reference data. This error occurs in Full Cache mode only. Either remove the duplicate key values, or change the cache mode to PARTIAL or NO_CACHE.
Watch out that you are not grabbing too many resources in the lookup. A couple of million records is probably not a good idea. And new is SSIS 2008 is that you can reuse your lookup cache in an other lookup.
 |
| SSIS 2008: Cache |
4) Filter in source
Where possible filter your data in the Source Adapter rather than filter the data using a Conditional Split transform component. This will make your data flow perform quicker because the unnecessary records don't go through the pipeline.
 |
| Filter in OLE DB Source, filter data in source |
5) Sort in source
A sort with SQL Server is faster than the sort in SSIS, partly because SSIS does the sort in memory. So it pays to move the sort to a source component (where possible). Note you have to set IsSorted=TRUE on the source adapter output, but setting this value does not perform a sort operation; it only indicates that the data it sorted. After that change the SortKeyPosition of all output columns that are sorted.
 |
| Advanced Editor for Source, sort data in source |
6) Join in source
Where possible, join data in the Source Adapter rather than using the Merge Join component. SQL Server does it faster than SSIS. But watch out that you are not making to complex queries because that will worsen the readability.
 |
| Unnecessary Join and Sorts |
7) Group in source
Where possible, aggregate your data in the Source Adapter rather than using the Aggregate component. SQL Server does it faster than SSIS.
 |
| Unnecessary Sorts, Join and Aggregate |
8) Beware of Non-blocking, Semi-blocking and Fully-blocking components in general
The dataflow consists of three types of transformations: Non-blocking, Semi-blocking and Fully-blocking. And as the names suggests, use Semi-blocking and Fully-blocking components rarly to optimize your packages.
Jorg Klein has written a interesting article about it with a list of which component is non-, semi- or fully blocking.
A summary of how to recognize these three types:
| Non-blocking | Semi-blocking | Fully-blocking |
Synchronous/asynchronous | Synchronous | Asynchronous | Asynchronous |
Number of rows in equal to rows out | True | Usually False | Usually False |
Collect all input before the can output | False | False | True |
New buffer created? | False | True | True |
New thread created? | False | Usually True | True |
Find more information about
(a)synchronous at Microsoft.
9) High Volumes of Data and indexes
Loading high volumes of data on a table with clustered and non-clustered indexes could take a lot of time.
The most important thing to verify is if all indexes are really used. SQL Server 2005 and 2008 provide information about index usage with to views: sys.dm_db_index_operational_stats and sys.dm_db_index_usage_stats. Drop all rarely used and unused indexes first. Experience teaches that there are often a lot of unnecessary indexes. If you are absolute sure that all remaining indexes are necessary you can drop all indexes before loading the data and to recreate them afterwards. The performance profit of that depends on the number of records. The higher the number of records the more profit you gain.
 |
| Drop and recreate indexes |
10) SQL Server Destination Adapter vs OLE DB Destination Adapter
If your target database is a local SQL server database, the SQL Server Destination Adapter will perform much better than the OLE DB Destination Adapter. However the SQL Server Destination Adapter works only on a local machine and via Windows security. You have to be absolute sure that your database stays local in the future otherwise you mapping will not work when moving the database.
Note: this is not a complete list, but just a top 10 of easy to implement but very effective ones. Tell me if you have items that should be in the top 10 of Performance Best Practices!
Note: Besides the Performance Best Practice there also is a
Development Best Practice.






























