You can compare a buffer going through a data flow, with a fire bucket going through a medieval line of people trying to extinguish a fire.
 |
| Buffers going through a data flow |
You can extinguish the fire faster by adding an extra line of people (parallel process) or my making the buckets larger (but not too large, otherwise they can't lift the buckets).
For this example I use a table with Google Analytics data from my blog staged in a database table.
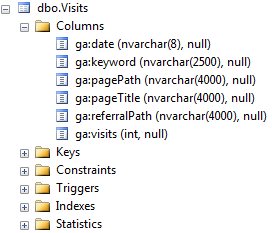 |
| Table with quite large columns |
Changing Buffer Size
By default the buffer size is 10 Megabytes (1024 * 1024 * 10 = 10,485,760 bytes). You can adjust this size for each Data Flow Task (see Data Flow Task Property DefaultBufferSize).
 |
| DefaultBufferSize 64KB <> 100MB |
I have a Package that pauses between buffers with a Script Component. This allows me to see how many records there are in one buffer. In my case 1 row of Google Analytics data is about 29000 bytes and if I run my Data Flow Task I can see that 360 rows of data fit in to my 10MB buffer.
 |
| 360 rows = ±10MB |
By making my buffer twice the size you will see that the number of rows in my buffer doubles. You can change the buffer size up to 100MB, but you have to remember that there are multiple buffers going through your data flow at the same time. If you don't have enough memory to fit all those buffers, then SSIS will swap memory to disk making it very slow! So only use bigger buckets if you can lift them...
 |
| 721 rows = ± 20MB |
Adjust row size
Never use a table as a datasource! Selecting a table is akin to "SELECT *..." which is universally recognized as bad practice(*). Always use a query. This allows you to skip unwanted columns and rows.
Unchecking "Available External Columns" at the Columns pane of the OLE DB Source Editor will prevent unwanted column in the buffer, but the data will have to go from SQL Server to SSIS. Removing unwanted column with a query will reduce the number of network packets going from a SQL Server machine to your SSIS machine.
 |
| Use query instead of whole table |
Let's remove an unwanted column to see the effect. Removing the nvarchar(4000) column [ga:referralPath] will reduce the total recordsize from 29030 to 21028 bytes. Now 497 rows instead of 320 will fit in my 10MB buffer.
 |
| Removing unwanted columns => more rows in buffer |
Adjust Column Size
Often column are just unnecessary too big in the source. If you can't change the source then you could change it in the source query with a CAST or CONVERT. For example the nvarchar(4000) column for page titles is way to big. My titles are not that long and the characters should fit in varchar. Let's CAST it to varchar(255) and see how many extra rows will fit in the buffer.
 |
| Resizing datatypes => more rows in buffer |
Now we have 787 rows instead of 320 rows in the 10mb buffer. That should speed up this package!
Note: if you change datatypes in an existing source query, then you have to uncheck and check the changed columns in the Columns pane of the OLE DB Source editor. This will refresh the metadata in the data flow. Otherwise you will get an error like: Validation error. DFT - Visits: DFT - Visits: Column "ga:pageTitle" cannot convert between unicode and non-unicode string data types.
 |
| Uncheck and check changed columns |
Add WHERE clause
Don't use a Conditional Split Transformation to remove records after an database table source. Instead use a WHERE clause in your source query. The Conditional Split is a so called Magic Transformation. It will only visually hide records instead of removing them from the buffer. And the records are unnecessary transported from SQL Server to SSIS.
 |
| Add WHERE clause instead of Conditional Split |
RunInOptimizedMode
This is a Data Flow Task property that, if set to true, will 'remove' unused columns and unused transformations to improve performance. Default value is true, but this property isn't the holy grail and you shouldn't rely on it while developing your packages.
 |
| RunInOptimizedMode |
Enable logging on Data Flow Task
There are some events that you could log to get information about the buffer:
User:BufferSizeTuning: This will tell you how many rows there were in the buffer.
- Rows in buffer type 0 would cause a buffer size greater than the configured maximum. There will be only 787 rows in buffers of this type.
- Rows in buffer type 0 would cause a buffer size greater than the configured maximum. There will be only 1538 rows in buffers of this type.
- The default buffer size is 10485760 bytes.
- Buffers will have 10000 rows by default.
- The data flow will not remove unused components because its RunInOptimizedMode property is set to false.
 |
| BufferSizeTuning and PipelineInitialization |
Performance Counters
SSIS comes with a set of performance counters that you can use to monitor the performance of the Data Flow Task. More about that in a later blog. For now see msdn.
Summary
Optimize Buffer Size
Use Source Query
Adjust Row Size
Adjust Column Size
Use Where clause
More info: Blog of Matt Masson, *Jamie Thomson, SQLCAT and MSDN
The "SSIS GoogleAnalyticsSource" plugin is deprecated?
ReplyDelete